“Quarantena”, “epidemia”, “epidemiologo”, “R0”, “lockdown”. Parole che fino a tre mesi fa erano scarsamente diffuse, nel giro di 90 giorni sono diventate parte integrante del nostro lessico quotidiano.
Certo, i protagonisti indiscussi della pandemia sono stati i numeri (decessi, contagi, guariti, ecc.) ma non poca attenzione è stata rivolta anche a come la comunicazione istituzionale è stata gestita e a cosa è stato scelto di comunicare. Uno dei metodi utilizzati per studiare questi ultimi due aspetti è proprio lo studio delle parole più utilizzate dai media per comunicare la crisi e del sentiment da essi diffuso.
Abbiamo intervistato sul tema la prof.ssa Emma Zavarrone, docente di Statistica sociale, che ha recentemente preso parte al progetto CO.ME.TA, una dashboard testuale – sviluppata, congiuntamente con il team di ricerca dell’Università di Napoli Federico II e al Centro di Ricerca Cecoms (IULM) – che consente di analizzare il sentiment dell’opinione pubblica rispetto alla pandemia, sulla base di alcuni media: Il Corriere, Il Sole 24ore, Repubblica, Fanpage, Twitter, The Guardian e NYTimes.
In tempo
di Coronavirus, quanto lo studio delle parole utilizzate dai media si è
rivelato importante per capire com'è stata gestita la comunicazione
istituzionale e gli effetti che essa ha avuto nella configurazione degli
scenari, delle decisioni collettive e nelle scelte e nei comportamenti dei
singoli?
Nel periodo del lockdown, l’attenzione degli scienziati è stata polarizzata in due macro-categorie: la prima dedicata a prevedere la fine del contagio o quantomeno l’inversione delle curve dei contagi e dei decessi e allora termini come “R0”,” tassi di mortalità pregressi”, “mediane e medie”, hanno contribuito a popolare il lessico quotidiano e ad evidenziare tristemente un livello di conoscenze statistiche non sempre adeguato sia nella classe politica che in quella giornalistica. La seconda, invece, meno densa della prima, ha visto il predominio dei temi sociali quindi la presenza di termini come “distanziamento”, “quarantena” e “regioni” ma anche “persone”. Ciò che ho notato, seguendo i diversi dibattiti (istituzionale, politico, medico, epidemiologico e quantitativo), è che pur essendo i nostri comportamenti quotidiani condizionati dalle parole, non si è dedicata abbastanza attenzione a “cosa” veniva comunicato. L’impressione generale che ho tratto è che la comunicazione istituzionale sia stata caratterizzata da tempi molto inusuali e assi semantici intorno al tema su cui si scriveva molto ripetitivi.
Wordcloud
Italia-Corriere della Sera
l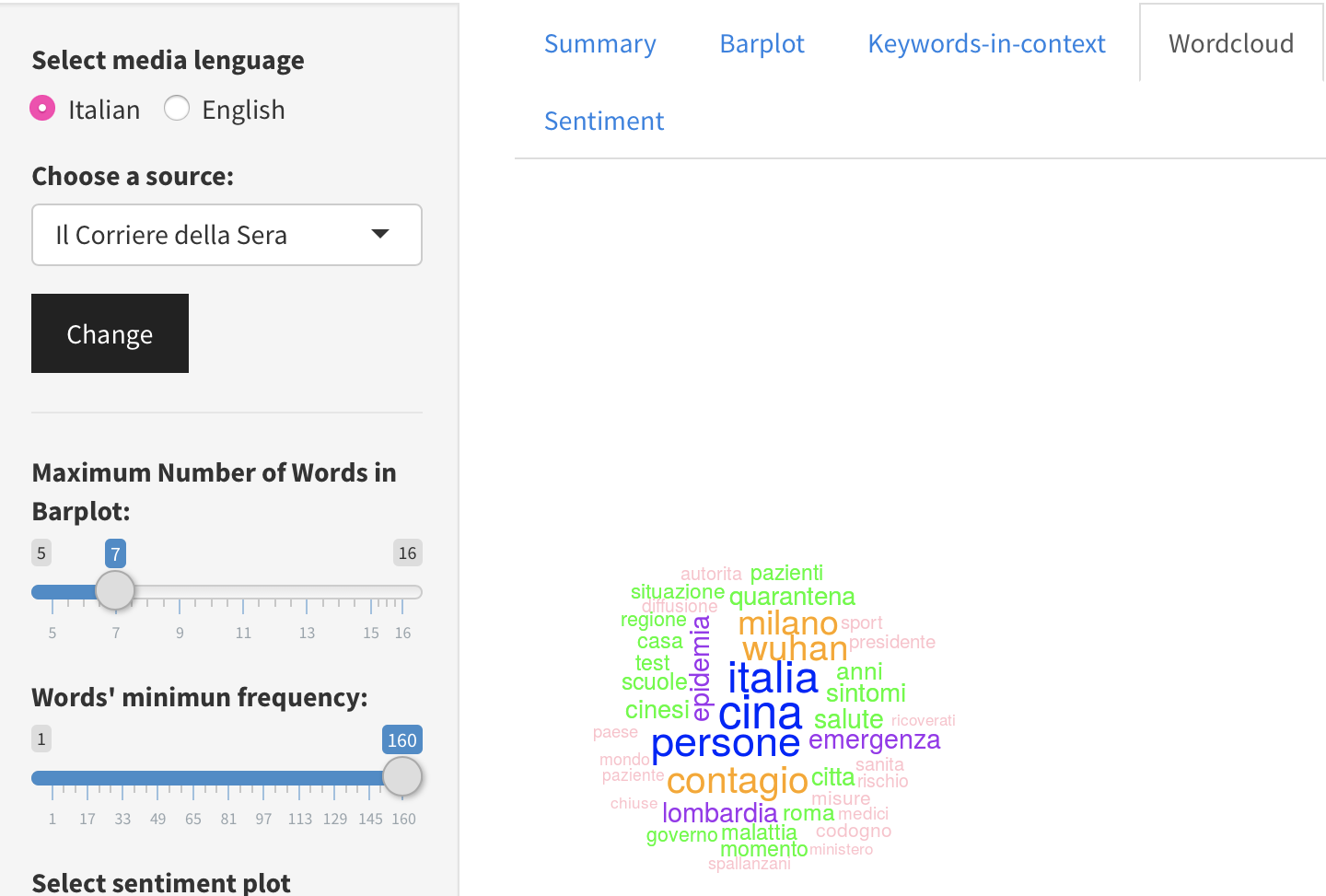
In cosa consiste la dashboard testuale CO.ME.TA? Da quale esigenza è nata e in che modo ha permesso l'analisi del sentiment diffuso dai media durante la pandemia? Come si differenzia da altri tools di sentiment analysis?
Ritengo che ogni progetto scientifico debba sempre prevedere l’aspetto divulgativo, (NdR, la prof.ssa è delegata del rettore
terza missione o similare) al fine di restituire al tessuto sociale in cui insiste, le conoscenze prodotte all’interno dell’università. Per questo motivo è stata sviluppata, congiuntamente con il team di ricerca dell’Università di Napoli Federico II e al Centro di Ricerca Cecoms (IULM), la dashboard, denominata CO.ME.T.A*. (COvid-19 Media Textual Analysis) che trova la sua sistemazione nell’ambito del Dipartimento di Studi Umanistici (IULM) ed è sviluppata ricorrendo a R e a Python.
La Textual Analytics alla base di CO.ME.TA (che al momento contiene circa 7 milioni di parole) consiste nell’insieme di quelle tecniche che consentono di acquisire dal web dati non strutturati e successivamente di procedere alla loro analisi applicando le metodologie di statistica multivariata in cui rientrano anche gli algoritmi di machine learning (AI). La sentiment analysis in CO.ME.T.A. è stata realizzata come la conseguenza di un processo di classificazione basato su algoritmi di machine learning visto l’assenza di dizionari adatti a spiegare e quantificare la valenza delle parole in questo specifico contesto.
Il punto di forza di questa dashboard è duplice: il primo risiede nella facilità di consultazione. Sebbene esistano in commercio alternative simili, esse sono caratterizzate da alti livelli di complessità e sottendono l’ipotesi principale che gli utilizzatori abbiano un livello elevato di conoscenze quantitative. La dashboard CO.ME.TA invece è stata dotata di una interfaccia grafica molto semplice: basta selezionare il quotidiano e il tipo di informazione che si desidera e il risultato è facilmente fruibile, pronto per essere inserito in un qualsiasi rapporto o a sua volta in un altro articolo o studio. Il secondo aspetto è connesso alla modularità delle analisi multivariate che si possono applicare. La produzione di wordcloud e di barplot associati ai singoli quotidiani, di reti tra tematiche e parole e, ovviamente, della visualizzazione del sentiment, rappresentano i principali moduli grafici supportati. Questi output sono disponibili anche in altre due lingue: inglese e spagnolo (quotidiani stranieri seguiti: The Guardian, Financial Times, The New York city, El Pais).
Quali sono
state le parole che più sono state utilizzate nel corso della pandemia e quali
i sentiment maggiormente diffusi?;
Dal 25 gennaio al 5 maggio sui principali quotidiani italiani ed esteri “Wuhan”, “Cina”, “contagio”, “Lombardia”, “Milano”, “emergenza” ed “epidemia” sono state le parole più frequenti. Mentre per quanto riguarda il sentiment, possiamo dire che a fine gennaio, nel nostro Paese era tendenzialmente positivo, ma si assiste a uno spostamento della polarità del sentiment verso la parte negativa dalla fine di febbraio.
E nel resto
d’Europa invece? Quali sono state le parole più usate nello stesso arco
temporale in Gran Bretagna e quale il maggior sentiment diffuso?
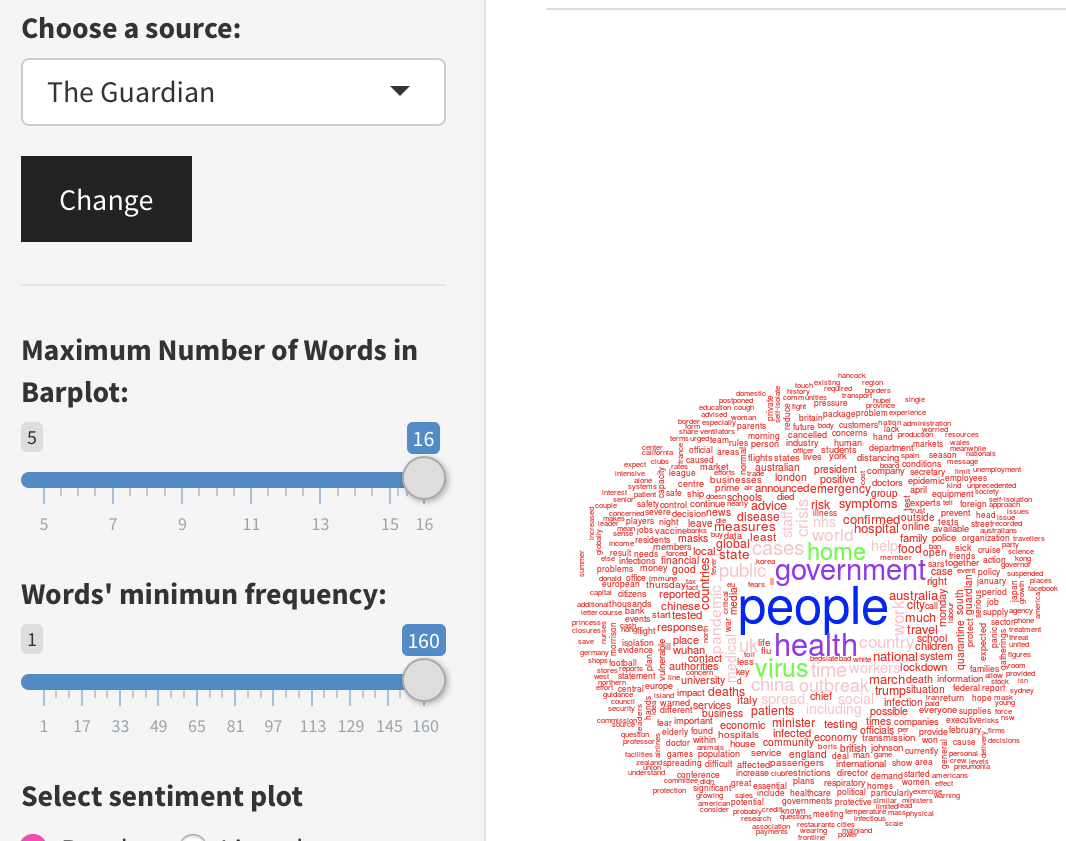
É interessante il confronto nel medesimo orizzonte temporale (25 gennaio – 5 maggio) con il the Guardian e, a parità di massima frequenza associata alle parole, il wordcloud riflette una storia diversa. C'è infatti un'unica sovrapposizione nel termine “people/ persone” mentre ricorrono maggiormente parole come“government”, “health” e “virus”, che non trovano una immediata corrispondenza nei testi italiani.
Wordcloud UK The Guardian
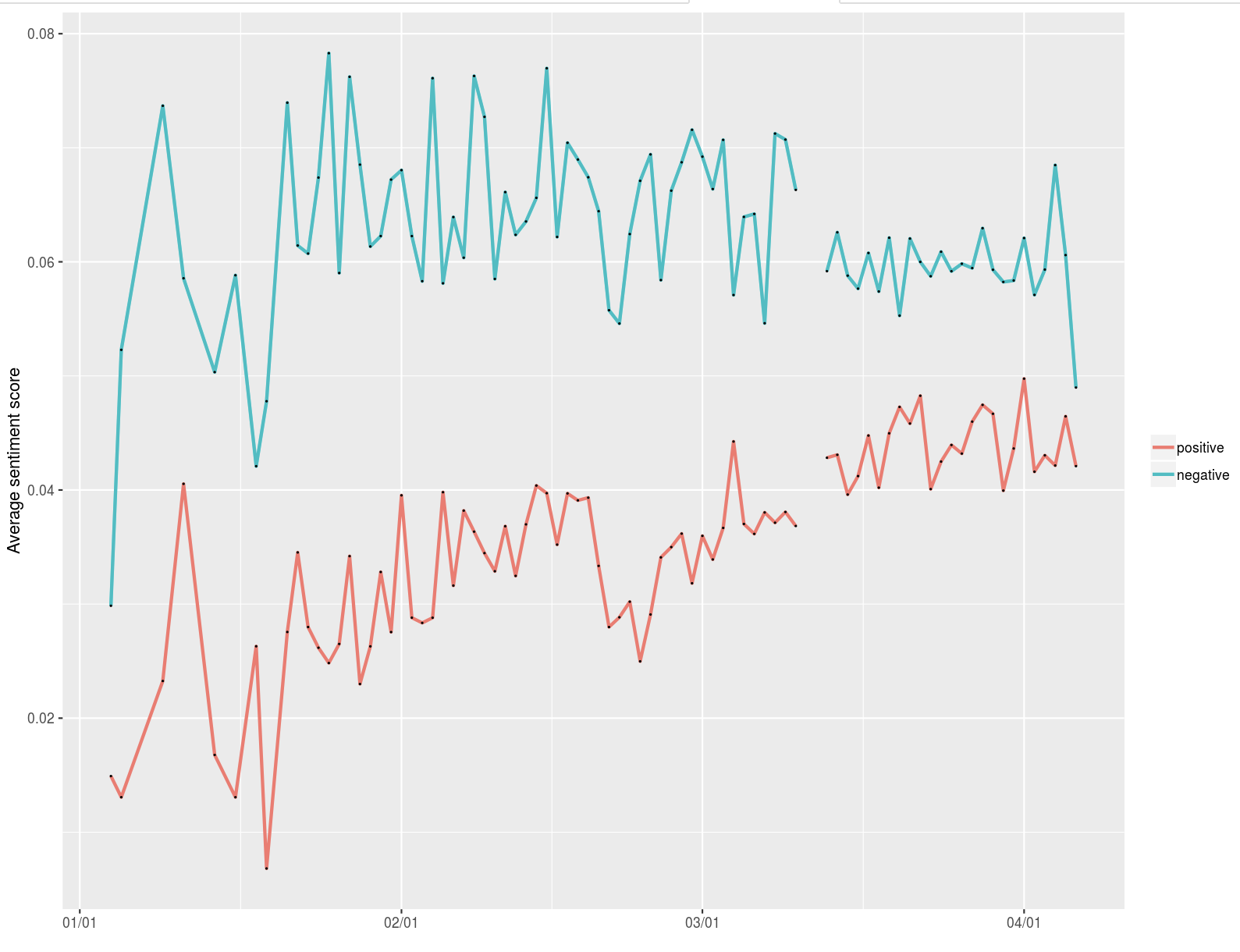
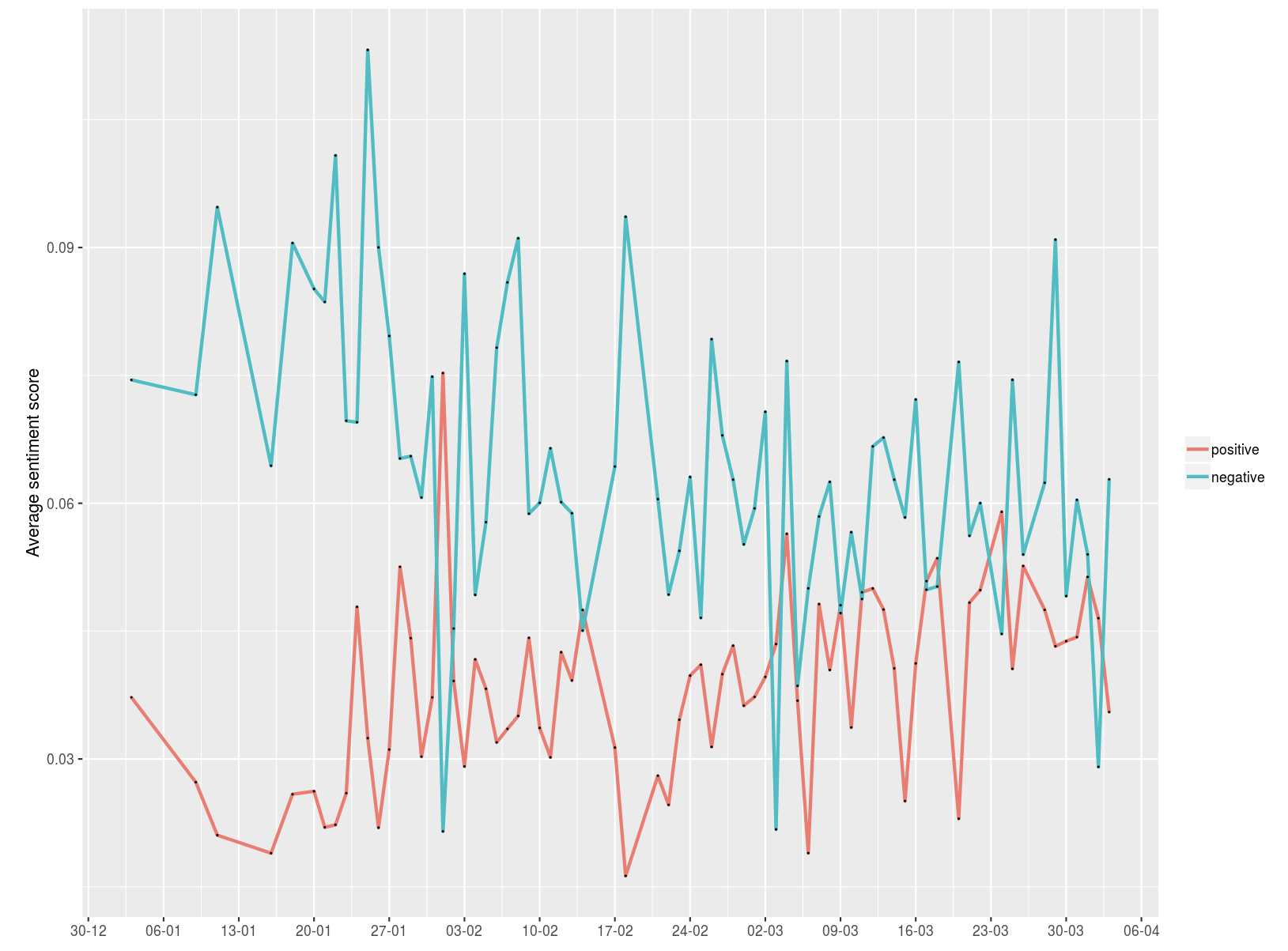
Il confronto del sentiment in Italia e in UK può essere infine inteso come un descrittore indiretto (proxy) di come sia stata gestita comunicazione Covid-19. In Italia il sentiment risulta all’inizio confuso e presenta addirittura un picco di positività. In UK, invece, l’andamento del sentiment è molto netto e si evidenziano due filoni: uno positivista ma di entità contenuta e l’altro pessimista molto impattante. Quando la pandemia ha iniziato a essere contenuta, questi due filoni sembrano convergere in punto di equilibrio.
Sentiment UK
Sentiment Italy
Il
"words tracing" e il "webscraping": due modelli efficaci di
raccolta dati sempre più indispensabili per le analisi predittive, che si sono
rivelati particolarmente efficaci anche in questo periodo di lotta contro il
virus. Come funzionano e qual è il futuro che intravedi per l'utilizzo di
questi modelli e di strumenti come CO.ME.TA?
Il webscraping concettualmente anticipa il words tracing poiché consente di raccogliere tutto il testo in prevalenza destrutturato disponibile sul web o sui social per poi sottoporlo dopo opportuni processi di data quality a tecniche come il words tracing. L’ambito del NLP (natural Language processing) negli ultimi anni ha visto uno sviluppo massivo coniugando un uso intensivo degli algoritmi riconducibili sia alle reti neurali, sia alle reti sociali e, infine, ai metodi della statistica multivariata. Il words tracing si colloca ampiamente nel primo cluster di metodologie agendo come un classificatore allenato a riconoscere di gruppi di frasi su cui effettuare la classificazione dei documenti. Il futuro è già iniziato: il NLP nelle sue diverse funzioni è alla base dei chatbot, di Siri, di Alexa, di Bixby e di tanti altri sistemi esperti che si basano sul linguaggio. Paradossalmente non esisteva finora un approccio simile per classificare i costrutti semantici ricorrendo alla textual analytics della comunicazione istituzionale e non. CO.ME.T.A. consente di colmare questo gap e non poteva che prendere vita nella nostra università beneficiando del mix delle competenze linguistiche, strategiche e quantitative. Ultimo ma non ultimo, è l’aspetto divulgativo di CO.M.E.T.A. che potrebbe essere di ausilio agli operatori del settore dotandoli di uno strumento semplice da utilizzare e duttile da personalizzare nell’ottica di esplorazione di tematiche differenti dal Covid-19.
Leggi un articolo di approfondimento sul Sole 24ore